

Running a frontier-tier model locally now takes only two commands—a significant shift from the complex setups required just a year ago.
On April 2, 2026, Google DeepMind released Gemma 4, a family of open-weight models distilled from Gemini 3. These models are designed to run on consumer hardware, reaching performance parity with models like GPT-5-mini on coding benchmarks, while offering native multimodal support for images and audio. Crucially, the release uses the Apache 2.0 license, enabling unrestricted commercial deployment. Following its launch, the consensus across developer communities is that this is a milestone release, though it comes with specific architectural trade-offs.
What Is Gemma 4?
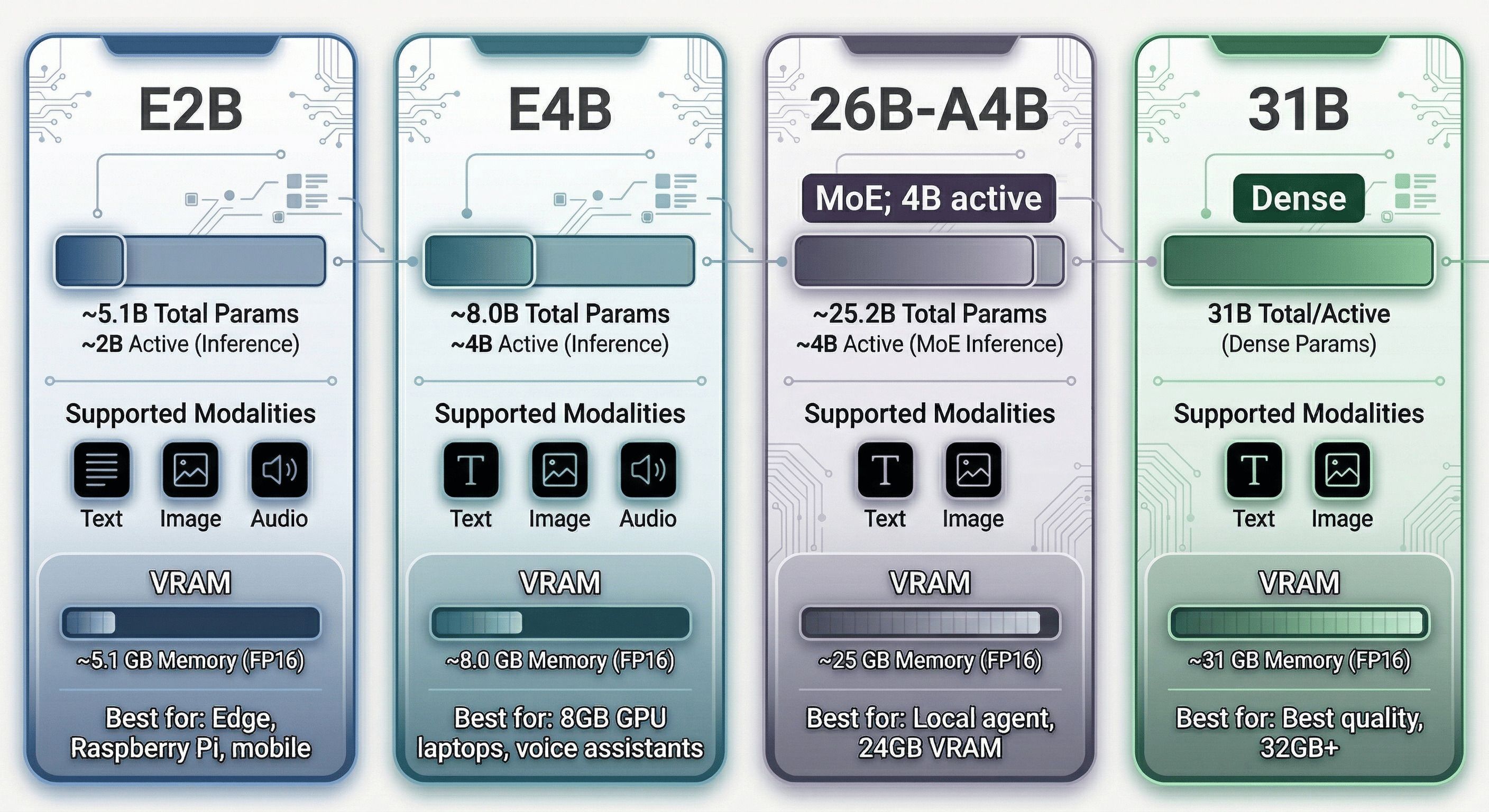
Gemma 4 is a family of four models ranging from an edge-optimized 2B-class system to a 31B dense model that competes with closed-source frontier models. Every variant is trained on over 140 languages, and features a common architectural core with per-model specializations.
Three key factors define this release:
- Apache 2.0 Licensing: Previous Gemma models utilized a custom license that created ambiguity for certain commercial agentic systems. Gemma 4 is fully Apache 2.0, allowing users to modify, deploy, and build products without restriction.
- Multimodal Input: All four models can process text and images. The two “Edge” variants (E2B and E4B) also support native audio input. Context windows reach up to 256K tokens for the larger models and 128K tokens for the edge variants.
- Local Inference Performance: The 26B Mixture of Experts (MoE) variant can achieve speeds of approximately 120–150 tokens/second on an RTX 4090 and up to 400 tokens/second on M5 MacBook Pro systems, thanks to its low active parameter count (~3.8B) during inference.
Note: Gemma 4 is an input-multimodal model; it processes text, images, and audio but outputs only text.
The Model Lineup; Pick Your Fighter
Gemma 4 ships in four variants. Understanding the naming is critical because Google’s choices here generated genuine controversy.
| Model | Total Params | Active (Inference) | Memory (Base) | Modalities | Best For |
|---|---|---|---|---|---|
| E2B | ~5.1B | ~2.3B | ~5.1 GB | Text, Image, Audio | Mobile, IoT, Raspberry Pi |
| E4B | ~8.0B | ~4.5B | ~8.0 GB | Text, Image, Audio | Laptops, Voice Assistants |
| 26B-A4B | ~25.2B | ~3.8B (MoE) | ~25.2 GB | Text, Image | Local Agents, 24GB VRAM |
| 31B | 30.7B | 30.7B (Dense) | ~31 GB | Text, Image | Reasoning, Coding, 32GB+ VRAM |
HuggingFace model cards:
- E2B:
google/gemma-4-e2b-it - E4B:
google/gemma-4-e4b-it - 26B-A4B:
google/gemma-4-26B-A4B-it - 31B:
google/gemma-4-31b-it
The “E” Naming Controversy
The “E” in E2B and E4B stands for Effective parameters; the compute budget during a forward pass, not the weight count. E4B runs like a 4B model computationally, but it has 8 billion weights sitting in RAM. You are not saving memory. You are saving compute.
“E4B is 8B weights marketed as 4B… classic bait and switch.” Multiple Hacker News users echoed this. The practical impact: if you’re GPU-constrained at 8GB VRAM, E4B fits (barely). But if you expected Raspberry Pi-level memory footprints from E2B based on the name, you’d be disappointed.
The naming logic is internally consistent; “effective” accurately describes the computational budget, not the storage cost; but it inverts the intuition most people have from model naming conventions where the number refers to parameters in memory.
Also notable: there is no 12B model. When a Gemma team member (canyon289) was asked about this on Hacker News, they acknowledged the gap but didn’t explain it. E4B appears to be the intended replacement for the 12B niche, though its benchmark performance sits meaningfully below what a 12B dense model would achieve.
Architecture Deep Dive
Gemma 4’s architecture is more interesting than it first appears. This section covers the seven innovations worth understanding.
Attention: Local and Global, Interleaved
Every Gemma 4 model alternates between two types of attention layers:
- Local (Sliding Window) Attention: each token only attends to the nearest N tokens within a sliding window. Efficient, O(n×w) complexity.
- Global Attention: full attention over the entire context. Expensive, O(n²) complexity, but necessary for long-range coherence.
The ratio:
- E2B: 4 local : 1 global
- E4B, 26B-A4B, 31B: 5 local : 1 global
Sliding window sizes: 512 tokens for E2B/E4B, 1024 tokens for the larger variants.
Key change from Gemma 3: The last layer of every Gemma 4 model is always a global attention layer. Gemma 3’s 4B model had a local attention layer as its final layer, which created a bottleneck for tasks requiring full-sequence summarization. That’s fixed.
Why does this matter? For a 256K token context, you’d be doing global attention only once every 5 or 6 layers; most of the compute stays cheap. The local layers do the heavy lifting for nearby relationships; the global layers integrate across the full context.
The Global Attention Efficiency Trio
Running global attention over 256K tokens naively would be prohibitively expensive. Gemma 4 applies three orthogonal optimizations to global attention layers specifically. Together they make long-context global attention fast enough to be practical.
Grouped Query Attention (GQA)
Standard multi-head attention has one Key and one Value per Query head, so the KV cache scales linearly with the number of heads. GQA groups multiple Query heads to share a single KV pair.
Gemma 4’s grouping is asymmetric:
- Local attention: 2 Query heads per KV head (modest grouping, fine at local scale)
- Global attention: 8 Query heads per KV head (aggressive grouping, critical for long contexts)
To compensate for the information loss from aggressive grouping, the Key dimensions are doubled in global attention layers. More information per KV pair, fewer KV pairs total.
Key-Value Tying (K=V)
Applied only in global attention layers of the 31B and 26B-A4B variants. Instead of learning separate Key and Value projections, the model sets Keys equal to Values: K = V.
This means the model only needs to store one set of vectors for global attention layers instead of two; effectively halving the KV cache for those layers. A separate RMSNorm is applied to the projection for Keys vs. Values even when they’re tied, which preserves the ability to apply different normalizations to the same underlying vectors.
The practical effect: the “KV cache” for global attention layers becomes a “K-cache only”; a meaningful memory reduction at long contexts where global layer KV contributions would otherwise dominate.
p-RoPE: Partial Rotary Positional Encoding
Standard RoPE (Rotary Positional Encoding) applies a rotation to every pair of dimensions in the attention head to encode position. At very long contexts, the lower-frequency rotation pairs accumulate noise; small rotations compound across 256K positions into drift that corrupts semantic information.
Gemma 4’s solution: only rotate the first 25% of dimension pairs (p=0.25). The other 75% have their rotations zeroed out entirely. Those high-frequency pairs preserve their semantic content without positional noise accumulation, while the 25% that do rotate handle positional discrimination efficiently.
p-RoPE is applied only to global attention layers, where long-context stability is most critical. Local attention layers use standard RoPE (they only see 512-1024 tokens, so noise accumulation isn’t a problem).
Per-Layer Embeddings; What “E” Actually Means
The E2B and E4B models use Per-Layer Embeddings (PLE); an additional lookup table for every transformer layer. This is the core innovation that makes the “E” naming meaningful.
Here’s how they work:
Standard embedding: when you feed a token into the model, it looks up one vector from a single embedding table at the input. That vector flows through all layers.
With PLE: the model maintains an additional embedding table per layer. At inference start, it does one lookup per token per layer; done once upfront, not repeated. Between each decoder block, a gating function weighs the per-layer embedding for the current token, projects it up to match the model’s hidden size (256-dim → 1,536-dim for E2B, → 2,560-dim for E4B), normalizes it, and adds it to the decoder’s output.
The effect: the model is constantly “reminded” of each token’s identity as information flows through the layers. Deep layers in a transformer can “forget” what they were originally processing; PLE counters this.
The flash storage trick: PLE tables are stored in flash memory, not (V)RAM. They’re streamed in once at inference start and discarded. This is why E2B’s “effective” parameters are only 2B; the PLE tables exist in flash, not in the GPU’s working memory. The idea is similar to the DeepSeek Engram approach.
KV cache sharing (E4B): in E4B, the last 18 of 42 transformer layers reuse the KV cache from the previous global attention layer instead of computing fresh K and V projections. The parameters saved from not needing those 18 K/V projections are reinvested in E2B into doubling the widths of the later MLP layers; trading attention memory for feedforward capacity.
PLE tables for E2B:
- Main vocabulary embedding: 262,144 tokens × 1,536 dimensions
- Per-layer embeddings: 262,144 tokens × 256 dimensions × 35 layers
That’s a lot of lookup tables. But because they live in flash and are accessed once, they don’t contribute to VRAM usage or per-token compute.
Mixture of Experts; The 26B-A4B
The 26B-A4B is the practical sweet spot for most local deployments. It runs at dense-4B speed while having the knowledge capacity of a 26B model. Here’s how.
The MoE setup:
- 128 experts total per MoE layer
- 8 routed experts selected per token via softmax + top-k
- 1 shared expert always activated (3× the size of a regular expert)
- Each routed expert is 1/3 the size of a standard MLP layer
So for any given token: 8 small routed experts + 1 large shared expert = effectively ~4B parameters active. The other 120 experts sit idle.
Key architectural decision; MoE as separate layers:
This is where Gemma 4 diverges from competitors. DeepSeek and Qwen run their shared experts in parallel with routed experts; one forward pass activates both simultaneously. Gemma 4 adds MoE blocks as sequential separate layers:
Token → Attention → MLP → MoE → next Attention → ...
The MoE layer is additive on top of the normal MLP, not a replacement for it. This is a deliberate architectural choice that differs from what DeepSeek-V2/V3 and Qwen-MoE do. The tradeoff: more compute per token (you still run the full MLP), but potentially better specialization since the MoE layer is a pure addition.
Gemma 4 also does not use AltUp or hyperconnections; simpler stack, easier to optimize and quantize.
Performance in practice: on an RTX 4090, the 26B-A4B runs at ~150 tokens/second generation speed. Qwen 3.5-35B-A3B (similar concept, 3B active) runs at ~100 tokens/second on the same hardware. The 50% speed advantage for comparable quality is the 26B-A4B’s headline case.
Vision Encoder
All Gemma 4 models are vision-capable. The vision encoder sits outside the LLM stack; it processes images into soft tokens that the language model consumes alongside text.
Two encoder sizes:
- E2B / E4B: 150M parameter ViT
- 26B-A4B / 31B: 550M parameter ViT
Both use 16×16 pixel patches.
Variable aspect ratio with 2D RoPE: instead of squishing all images into a fixed square, Gemma 4 splits the positional embedding in half; one half encodes horizontal position, the other encodes vertical position. Images are adaptively resized to preserve their original aspect ratio, with padding as needed. This prevents distortion artifacts that occur when forcing a 16:9 landscape photo into a square grid.
Soft token budget: images are represented in the LLM’s embedding space at one of five resolution levels; 70, 140, 280, 560, or 1120 tokens. The resolution must be a multiple of 48 pixels (3 patches of 16 pixels, merged via 3×3 average pooling into a single embedding). A 280-token budget means up to 9 × 280 = 2,520 patches before pooling. You trade resolution for context budget depending on your use case.
Projection to LLM space: ViT patch embeddings are projected via a linear layer + RMSNorm to match the LLM’s hidden dimension.
Audio Encoder (E2B/E4B Only)
The two smallest Gemma 4 models can process audio. The 26B-A4B and 31B cannot.
The audio encoder is Conformer-based; a Transformer encoder augmented with a convolutional module that’s well-suited to the local-then-global structure of speech signals.
Processing pipeline:
- Raw audio waveform
- Mel-spectrogram extraction (convert to frequency representation)
- Chunking into fixed-length segments
- 2D convolutional downsampling (reduce temporal resolution)
- Conformer encoder (Transformer + convolution)
- Linear projection to LLM embedding space
The output is soft tokens; continuous embeddings, not discrete tokens; that the LLM processes alongside text and vision tokens.
“The smaller models have an audio thing glued onto them, it’s not native to the model like photo/video.” The architecture supports audio, but it wasn’t trained end-to-end from day one the way the vision encoder was. For production voice applications, this matters; the audio understanding may be shallower than the image understanding.
The 260K Vocabulary Problem
All Gemma 4 models; E2B, E4B, 26B-A4B, 31B; use a vocabulary of 262,144 tokens (2^18, or ~260K). This is inherited from Gemini 3 via distillation, and it’s the same vocabulary used in Gemma 3 and Gemma 3n.
For context: Llama uses ~32K tokens. Mistral uses ~32K. Qwen 3.5 uses ~150K. Gemma 4 is at 260K; roughly 8× larger than typical open models.
Why does this matter?
“Such a giant vocab is strange for a 2B model, since the output embedding matrix consumes most of the parameters.”
For E2B, the main embedding table alone is: 262,144 tokens × 1,536 dimensions ≈ 400M parameters; a disproportionate chunk of the “2B effective” budget. The PLE tables add more: 262,144 × 256 × 35 layers ≈ another 2.4 billion values (though stored in flash). This is parameter budget that, in a model with a smaller vocabulary, would go into the transformer layers themselves.
Upside: the large vocabulary enables excellent tokenization efficiency across 140+ languages. Code, scientific notation, and multilingual text get compressed more efficiently; fewer tokens per character, more context for the same length text.
Downside for quantization: a 260K embedding table is harder to quantize cleanly than a 32K one. Standard Q4_K_M applies relatively uniform quantization pressure. Unsloth’s Dynamic 2.0 addresses this by analyzing each layer’s sensitivity individually and applying higher precision where it matters; including the embedding table. This is one reason the Unsloth GGUF variants (prefixed UD-) are worth preferring over standard Q4_K_M for Gemma 4 specifically.
Benchmarks; Where It Wins, Where It Doesn’t
Here is the full benchmark comparison from HuggingFace model cards, compiled by the community:
| Model | MMLU-Pro | GPQA Diamond | LiveCodeBench v6 | Codeforces ELO | TAU2-Bench | MMMLU | HLE (no tools) | HLE (tools) |
|---|---|---|---|---|---|---|---|---|
| Gemma 4 31B | 85.2% | 84.3% | 80.0% | 2150 | 76.9% | 88.4% | 19.5% | 26.5% |
| Gemma 4 26B-A4B | 82.6% | 82.3% | 77.1% | 1718 | 68.2% | 86.3% | 8.7% | 17.2% |
| Gemma 4 E4B | 69.4% | 58.6% | 52.0% | 940 | 42.2% | 76.6% | ; | ; |
| Gemma 4 E2B | 60.0% | 43.4% | 44.0% | 633 | 24.5% | 67.4% | ; | ; |
| Gemma 3 27B (no think) | 67.6% | 42.4% | 29.1% | 110 | 16.2% | 70.7% | ; | ; |
| GPT-5-mini | 83.7% | 82.8% | 80.5% | 2160 | 69.8% | 86.2% | 19.4% | 35.8% |
| Qwen 3.5-122B-A10B | 86.7% | 86.6% | 78.9% | 2100 | 79.5% | 86.7% | 25.3% | 47.5% |
| Qwen 3.5-27B | 86.1% | 85.5% | 80.7% | 1899 | 79.0% | 85.9% | 24.3% | 48.5% |
| Qwen 3.5-35B-A3B | 85.3% | 84.2% | 74.6% | 2028 | 81.2% | 85.2% | 22.4% | 47.4% |
What the numbers say
Gemma 4 31B is competitive with GPT-5-mini across the board. On Codeforces ELO (competitive programming), it actually ties GPT-5-mini at 2150. This is the most striking result: an open-weight model running locally matching a closed-source frontier on coding.
Gemma 4 E4B beats Gemma 3 27B on every single benchmark; dramatically in some cases (52% vs 29% on LiveCodeBench). This is a real generational improvement for small models.
The Qwen problem: Gemma 4 consistently underperforms Qwen 3.5 variants on MMLU-Pro, GPQA Diamond, and especially HLE-with-tools. Qwen 3.5-27B outperforms even Gemma 4 31B on GPQA Diamond (85.5% vs 84.3%). The smaller Gemma models are outpaced by Qwen models with similar or fewer total parameters.
The “benchmaxxing” debate
Developer community: “Featuring the ELO score as the main benchmark is VERY misleading. The big dense Gemma 4 model does not seem to reach Qwen 3.5 27B dense model in most benchmarks. The release is a bit disappointing.”
The counter: “You can use this model for about 5 seconds and realize its reasoning is in a league well above any Qwen model, but instead people assume benchmarks that are openly getting used for training are still relevant.”
This is a genuine tension. Chinese model vendors have known access to public benchmark test sets, and training on or near these distributions is a reasonable suspicion. Subjective quality impressions from practitioners often diverge from benchmark rankings. Simon Willison’s informal SVG generation test (a “pelican swimming in a pond”) produced what he called the best output he’d seen from a model running on his laptop (128GB M5). Benchmark numbers and practical impressions don’t always point the same direction.
SQL benchmark
On an independent SQL generation benchmark (sql-benchmark.nichlothian.com):
- E4B: 15/25; competitive with Qwen 3.5-9B in thinking mode
- E2B (4-bit quantized): 12/25; tied with NVIDIA Nemotron-3-Nano-4B, best 4B model tested
A 12/25 score from 4-bit quantized E2B on SQL generation is genuinely useful for edge deployments.
Running Gemma 4 Locally; Two Commands Away
The fastest path to running the recommended model (26B-A4B at Q4_K_M quantization):
llama.cpp
brew install llama.cpp --HEAD
llama-server -hf ggml-org/gemma-4-26B-A4B-it-GGUF:Q4_K_M
That’s it. The first command installs llama.cpp from HEAD (required for Gemma 4 support). The second downloads the quantized model from HuggingFace and starts an OpenAI-compatible server on localhost:8080. No Python environment, no CUDA setup, no Docker.
To disable thinking/reasoning mode: append --reasoning off.
Ollama
ollama pull gemma4:26b-a4b-it-q4_K_M
ollama run gemma4:26b-a4b-it-q4_K_M
Inference speed by hardware
| Hardware | Model | Quantization | Generation Speed |
|---|---|---|---|
| RTX 4090 (24GB) | 26B-A4B | UD-Q4_K_XL | ~150 tok/s |
| RTX 4090 (24GB) | 31B | UD-Q4_K_XL | ~5 tok/s (CPU offload) |
| RX 7900 XTX (24GB) | 26B-A4B | UD-Q4_K_XL | 120 tok/s @ 1K ctx |
| RX 7900 XTX (24GB) | 26B-A4B | UD-Q4_K_XL | 71 tok/s @ 128K ctx |
| M5 MacBook Pro (128GB) | 26B-A4B | Q4_K_M | 400 tok/s |
| M4 Mac Mini (24GB) | 26B-A4B | Q4_K_M | 28 tok/s |
| M1 Max (64GB) | 26B-A4B | Q4_K_M | 16–50 tok/s |
| M3 Max (36GB) | 26B-A4B | Q4 | smooth |
| M1 MacBook (16GB) | 26B-A4B | Q4_K_M | 8 tok/s |
The sweet spot: 26B-A4B at Q4_K_M on a 24GB VRAM card. The model loads in ~18GB, leaving ~6GB headroom for context and KV cache. You get ~120-150 tok/s on NVIDIA, comparable speed on AMD with ROCm.
The 31B dense problem: 31B at any useful quantization exceeds 24GB VRAM once you add KV cache. The static SWA (Sliding Window Attention) KV cache alone costs 3.6GB. IQ4_XS quantization brings weights to 15.2GB, but you’re CPU-offloading and paying ~5 tok/s. For 31B quality on a 24GB card, wait for QAT (quantization-aware training) versions. For now, 31B really wants 32GB+ VRAM.
Recommended inference settings
From Unsloth (Daniel Han, who trained the model’s calibration sets):
temperature: 1.0
top_p: 0.95
top_k: 64
EOS token: <turn|>
Thinking trace token: <|channel>thought\n
Note: Google recommends temperature 1.0 for benchmark reproducibility. Many practitioners prefer 0.7-0.8 for creative or conversational use. To disable thinking entirely in llama.cpp: --reasoning off.
Unsloth Dynamic 2.0; why it matters for Gemma 4
Unsloth’s UD- quantization variants are different from standard GGUF quants. Dynamic 2.0 does per-layer sensitivity analysis using a >1.5M token calibration dataset. For each layer, it determines the minimum quantization level that preserves quality. The result: embedding layers and attention projections that are sensitive to precision get quantized less aggressively, while feedforward layers that are more robust get quantized more.
For Gemma 4 specifically, this matters because of the 260K vocabulary embedding table. A standard Q4_K_M quantizes the embedding table at the same bit depth as everything else. Unsloth’s approach can keep embedding rows at higher precision where token frequency distributions make it worthwhile. The UD-Q4_K_XL variant is the recommended Unsloth pick for 24GB systems.
What the Community Actually Thinks
The positives
On Apache 2.0 licensing:
“Apache 2.0 is a big shift here. Previous Gemma licenses made it a legal gray zone for agent deployments, especially BYOK setups. Now it’s genuinely free to deploy commercially.”
“Finally open weights that don’t make us slaves to their garbage APIs.”
On local performance:
“Two commands to run a frontier-tier model locally. A year ago this would have been a 20 step setup guide with CUDA driver hell.”
“You can use this model for about 5 seconds and realize its reasoning is in a league well above any Qwen model.”
On the 26B-A4B practical value:
One user ran Gemma 4 26B-A4B and Qwen 3.5-35B-A3B side-by-side on an RTX 4090 as Claude Code agent backends. Gemma 4: ~40 tok/s for a 4B-active model. Qwen 3.5-35B-A3B: ~12 tok/s for a 3B-active model. The inference speed advantage is real and compounds over long agentic sessions.
On the E4B model specifically:
“Good enough that I can see it replacing Claude.ai for some things”; at just 8GB VRAM.
The negatives
Tool calling was broken at launch. Multiple users reported failures with function calling. A chat template bug in llama.cpp was patched via PR #21326 within days. The underlying model supports function calling, but the inference infrastructure wasn’t fully ready on day one. For agentic workflows, tool reliability is table stakes; this matters.
The “E” naming controversy. Already covered, but worth re-emphasizing: this created genuine confusion. If you’re recommending Gemma 4 to non-technical users, explain that “E2B needs 5GB of RAM, not 2GB.”
No 12B model. There’s a well-populated tier of 9-12B models (Qwen 3.5-9B, Llama 3.1-8B) that’s ideal for mid-range laptops with 8-16GB VRAM. E4B sort of fits this niche but is architecturally unusual (PLE, KV cache sharing) in ways that may affect some applications.
Smaller models underperform Qwen. On MMLU-Pro, GPQA Diamond, and HLE, Qwen 3.5-27B beats Gemma 4 31B. E4B (8B weights) is meaningfully below Qwen 3.5-9B. If your primary metric is knowledge benchmarks, Qwen is the current leader at most size classes.
The agentic coding gap. At least one Hacker News user ran a structured Rust project test through OpenCode with multiple models. Qwen 3.5-27B “significantly outperformed” Gemma 4 26B-A4B. For coding-heavy agentic workflows specifically, Qwen maintains an advantage.
The debates
Benchmark gaming accusations: The Codeforces ELO (2150 for G4 31B) was specifically called out as misleading, since ELO-style scores on competitive programming can be gamed by training strategy more easily than raw correctness benchmarks. This is a live debate in the community.
MoE “sqrt rule”: Some HN users applied the rule of thumb sqrt(total_params × active_params) to estimate “effective intelligence”; giving 26B-A4B a score of ~sqrt(26B × 4B) ≈ 10B dense equivalent. Others argued this rule is outdated and doesn’t apply to modern MoE architectures. No consensus.
Thinking trace reliability: Users specifically flagged that Gemma 4’s thinking traces can produce convincing-looking but wrong reasoning chains. The model “hallucinated tool use and verification steps, producing wrong answers while appearing to reason correctly.” Long thinking traces don’t guarantee correctness.
What people want next (from the Gemma team)
Community requests logged by canyon289 (Gemma team member on HN):
- QAT (Quantization-Aware Training) versions; multiple urgent requests for models trained to be quantized, not just post-hoc quantized
- Larger models; 60B-200B range to compete with Qwen 3.5-122B-A10B
- Audio for larger models; E-series audio support but not 26B/31B
- Audio output; no Gemma variant generates audio
- Improved tool calling; functional from day one, not patched later
- Qualcomm NPU support;
.litertlmfiles for on-device Qualcomm hardware
One unverified claim making rounds: Jeff Dean’s slides apparently hinted at a 124B MoE variant that was not included in this release. Nothing confirmed.
What’s Missing and What’s Next
The model family gaps:
Gemma 4 has a dumbbell shape; two tiny E-series models and two large models, with nothing in the 12-20B range. This leaves a gap that Qwen 3.5-9B and Qwen 3.5-27B fill comfortably. E4B at 8B weights is the closest, but its compute behavior (2-4B effective) makes it behave smaller than its weight count suggests.
Multimodal gaps:
The 26B-A4B and 31B models don’t support audio. If you need audio + large model, that combination doesn’t exist in the Gemma 4 family yet. And no Gemma 4 model generates images, audio, or video; text output only, full stop.
Tool calling reliability:
The infrastructure-level tool calling bugs at launch are patched, but the model itself was reportedly unreliable on complex multi-step tool use compared to the best closed models. Agentic coding and orchestration workflows still favor Qwen 3.5 or GPT-5-mini for tool-heavy tasks.
The 260K vocab tradeoff:
Inheriting Gemini’s tokenizer gives Gemma 4 excellent multilingual coverage, but it’s architecturally awkward for edge-scale models. Standard quantization is less effective on large embedding tables. QAT versions would help significantly; and are among the most-requested additions from the community.
What’s next:
- Apple is reportedly distilling Google models for Siri’s next update
- Modular MAX published a day-zero implementation claiming “fastest open-source performance for Gemma 4 on NVIDIA Blackwell and AMD MI355”
- MLX-optimized versions for Apple Silicon appeared within days of launch
- The llama.cpp tool calling issue was patched within days; the toolchain moves fast
TL;DR; Quick Reference
Which model should you use?
Do you have ≤8GB VRAM or need audio input?
→ E4B (voice assistant, mobile, laptop)
Do you have ≤8GB VRAM and need the smallest possible model?
→ E2B (Raspberry Pi, edge deployment)
Do you have 18-24GB VRAM and want the best local agent?
→ 26B-A4B at Q4_K_M or UD-Q4_K_XL (fastest, most capable per VRAM GB)
Do you have 32GB+ VRAM and want maximum quality?
→ 31B (best reasoning, best coding, closest to GPT-5-mini)
Do you need tools/agents to work reliably today?
→ Consider Qwen 3.5-27B or wait for Gemma 4 QAT versions
One-liners
llama.cpp (recommended for fine control):
brew install llama.cpp --HEAD && llama-server -hf ggml-org/gemma-4-26B-A4B-it-GGUF:Q4_K_M
Ollama (easiest):
ollama run gemma4:26b-a4b-it-q4_K_M
llama.cpp without thinking:
llama-server -hf ggml-org/gemma-4-26B-A4B-it-GGUF:Q4_K_M --reasoning off